
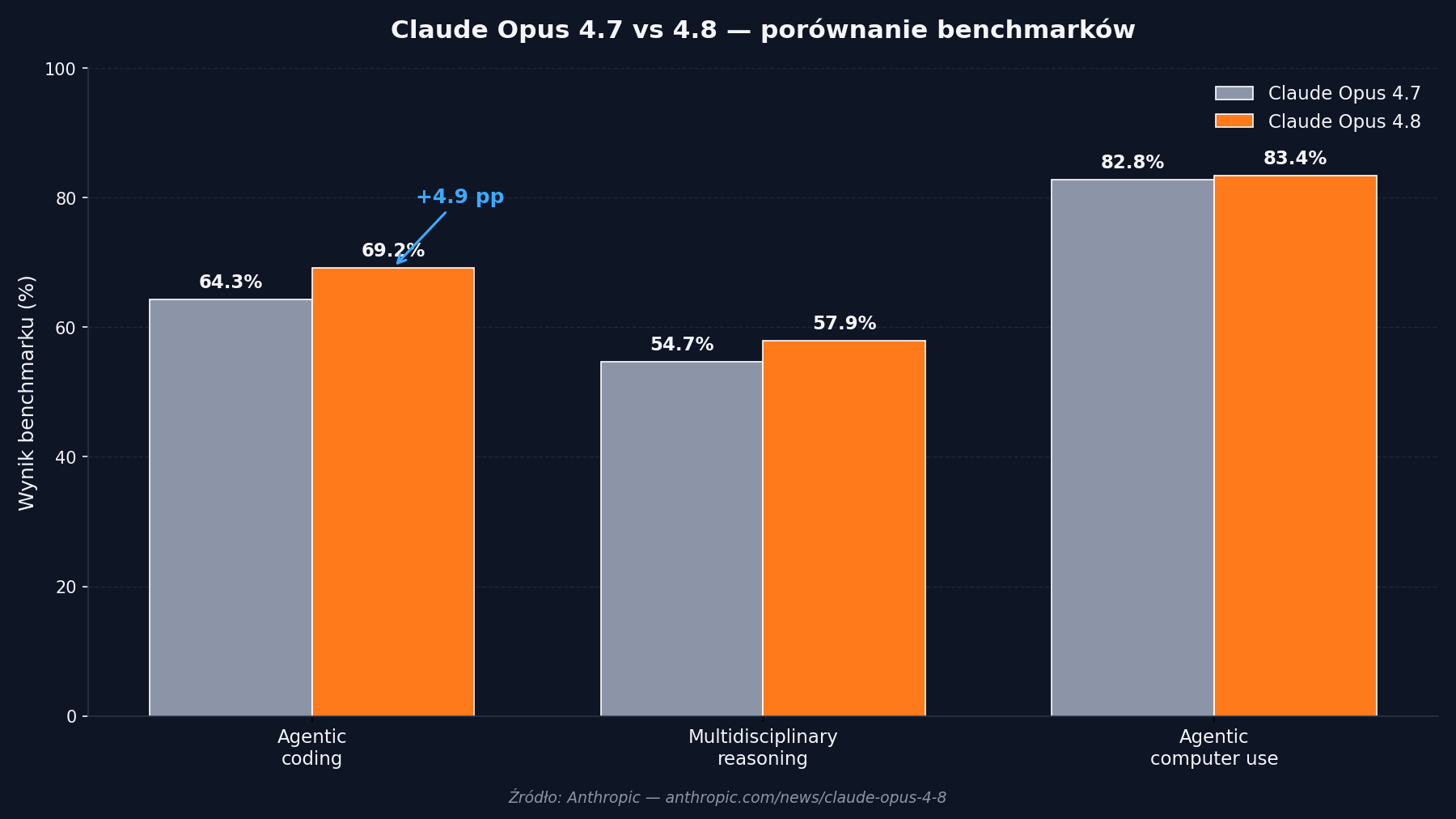
Anthropic wypuścił Claude Opus 4.8 — inkrementalny upgrade, który na pierwszy rzut oka wygląda na drobny tuning, ale jego konsekwencje dla zespołów IT są zaskakująco konkretne. Skok w agentic coding z 64,3% do 69,2% oraz czterokrotnie mniejsza szansa, że model przepuści błąd w kodzie, zmieniają kalkulację dla każdej firmy, która rozważa wdrożenie asystenta AI w pipeline programistycznym (Anthropic — źródło).
Dla polskich zespołów to jasny sygnał: bariera „jeszcze nie ufam modelom w produkcji" topnieje szybciej, niż wynikałoby z samych ogłoszeń marketingowych. W tym tekście rozbieramy, co realnie zmienia Opus 4.8, gdzie kończy się hype, a zaczyna twarda korzyść biznesowa, oraz jakie decyzje warto podjąć w najbliższych tygodniach.
Spis treści
- Co zmienia Claude Opus 4.8
- Agentic coding 69,2% — twarde liczby
- Honesty i czterokrotnie mniej przeoczonych błędów
- Cena bez zmian — co to mówi o strategii Anthropic
- Co powinny zrobić polskie zespoły IT
- Najczęściej zadawane pytania
Co zmienia Claude Opus 4.8
Opus 4.8 nie jest rewolucją — Anthropic sam komunikuje go jako inkrementalny upgrade. Ale w tej generacji modeli to słowo zaczyna oznaczać coś innego niż rok temu. Inkrement na pojedynczym benchmarku to dziś realne minuty oszczędzone w code review, mniej godzin spalonych na łapaniu regresji oraz wyższy próg, od którego zespoły zaczynają delegować całe podtaski agentowi zamiast operatorowi-człowiekowi (Anthropic — pełny opis zmian).
Trzy kluczowe wskaźniki, które Anthropic publikuje przy okazji premiery:
- Agentic coding: 64,3% → 69,2% (wzrost o 4,9 punktu procentowego)
- Multidisciplinary reasoning: 54,7% → 57,9%
- Agentic computer use: 82,8% → 83,4%
Wzrost w agentic coding jest najbardziej spektakularny — i jednocześnie najbardziej praktyczny dla działów IT, które zaczynają eksperymenty z autonomicznymi agentami w pipeline'ach CI/CD oraz lokalnych narzędziach typu Claude Code.
Agentic coding 69,2% — twarde liczby
Czym właściwie jest „agentic coding" w odróżnieniu od zwykłego autocomplete? To benchmark mierzący zdolność modelu do samodzielnego doprowadzenia zadania programistycznego do końca — przeczytania repo, zaplanowania zmiany, modyfikacji wielu plików, uruchomienia testów i poprawienia własnych błędów w pętli. W praktyce to różnica między „pomocnikiem podpowiadającym fragmenty" a „junior developerem, który zamyka ticket".
Co znaczy skok z 64,3% do 69,2%? Każdy procent oznacza inną kategorię tasków, które stają się wykonalne autonomicznie — bez human-in-the-loop na każdym kroku. Z perspektywy zespołów, które już używają Claude Code (zalecamy zacząć od naszego praktycznego przewodnika po Claude Code), zmiana jest odczuwalna w trzech miejscach:
- Refaktory wieloplikowe — mniej zgubionych importów, mniej „zostawionych w pół-kroku" plików.
- Generowanie testów — model częściej trafia w realne edge case zamiast bezpiecznych happy path.
- Debugging między warstwami — model rzadziej proponuje fix-y, które łatają symptom zamiast przyczyny.
Dla firmy, która płaci za każdą godzinę developerów, te procenty zamieniają się w konkretne oszczędności miesięczne — pod warunkiem, że zespół wie, jak włożyć agenta we właściwe miejsce procesu (Anthropic — dokumentacja).
Honesty i czterokrotnie mniej przeoczonych błędów
To dla nas najciekawsza zmiana — i najbardziej niedoceniana w nagłówkach. Anthropic chwali się, że Opus 4.8 jest ~4× rzadziej skłonny pozwolić, by błąd w kodzie pozostał niezauważony (źródło: Anthropic).
Dlaczego to ważne? W code review to nie liczba znalezionych błędów decyduje o jakości — decyduje liczba przeoczonych. Model, który w 80% przypadków znajduje błąd, ale w 20% zapewnia „wszystko ok" mimo realnego problemu, jest gorszy niż brak modelu, bo usypia czujność człowieka. Anthropic celuje dokładnie w ten problem: lepsza „honesty" oznacza, że agent częściej mówi „tu jest problem, którego nie umiem rozwiązać" zamiast wygenerować pewnie brzmiącą halucynację.
Co to znaczy operacyjnie? Trzy konsekwencje:
- Mniejsze ryzyko false negatives — model rzadziej daje zielone światło wadliwemu kodowi.
- Większa wiarygodność feedbacku — komentarz review od agenta zyskuje wagę bliższą juniorowi-człowiekowi.
- Realny potencjał integracji w CI — agent może być bramką jakości kodu, nie tylko sugestią dla człowieka.

Cena bez zmian — co to mówi o strategii Anthropic
To moim zdaniem najbardziej znaczący sygnał całej premiery: cena Opus 4.8 nie różni się od 4.7 (Anthropic — ogłoszenie). W kontekście rynku, na którym konkurenci co kwartał komunikują nowe poziomy cenowe za flagowe modele, utrzymanie ceny przy realnym wzroście jakości jest agresywnym ruchem konkurencyjnym.
Dla polskiej firmy outsourcingowej, agencji softwarowej czy in-house zespołu IT oznacza to jedno: stosunek wartości do kosztu Claude'a właśnie wzrósł — bez konieczności renegocjacji budżetu z CFO. To okno, w którym warto zrobić uczciwy benchmark własnego procesu kodowania z agentem i bez.
| Wskaźnik | Opus 4.7 | Opus 4.8 | Zmiana |
|---|---|---|---|
| Agentic coding | 64,3% | 69,2% | +4,9 pp |
| Multidisciplinary reasoning | 54,7% | 57,9% | +3,2 pp |
| Agentic computer use | 82,8% | 83,4% | +0,6 pp |
| Cena | — | — | bez zmian |
Co powinny zrobić polskie zespoły IT
Trzeźwa rekomendacja z perspektywy praktyka: nie zmieniaj wszystkiego dlatego, że wyszedł nowy model. Potraktuj jednak Opus 4.8 jako pretekst do trzech konkretnych ruchów:
- Audyt obecnego pipeline'u AI — gdzie używasz słabszego modelu tam, gdzie premium-grade reasoning naprawdę by się opłacił?
- Re-test krytycznych workflow — jeśli pół roku temu odrzuciliście agenta jako „za mało dokładny", powtórzcie test. Próg 69,2% może być właśnie tym, czego brakowało.
- Polityka AI w firmie — większa „honesty" modelu zmienia kalkulację compliance, w tym to, co możesz delegować agentowi w kontekście RODO i kodu klienta (warto przejrzeć nasz poradnik wdrożenia polityki AI w firmie).
Jak nie zmarnować upgrade'u
Najczęstszy błąd, który widzimy u klientów: zespół wdraża nowy model, ale nie zmienia struktury zadań, które mu deleguje. Opus 4.8 odblokowuje większe, bardziej autonomiczne taski — jeśli dalej będziesz pytał go o pojedyncze funkcje, nie zobaczysz różnicy. Trzeba przeprojektować sposób formułowania ticketu, tak by agent miał kontekst do podejmowania decyzji architektonicznych w obrębie pojedynczego zadania.
Twój zespół na fali Opus 4.8
Jako firma IT pomagamy włożyć Claude Opus 4.8 we właściwe miejsce procesu — bez chaosu, bez budżetu spalonego na eksperymenty bez planu. Nasze wdrożenie AI w firmie zaczyna się od audytu obecnego pipeline'u, a kończy mierzalnym SLA. Jeśli zespół potrzebuje twardych umiejętności od podstaw, sprawdź szkolenia Claude Code oraz szkolenia AI dla firm.
Najczęściej zadawane pytania
Czy warto migrować z Opus 4.7 na 4.8?
Tak, jeśli już korzystasz z Opus 4.7 w workflow programistycznym — cena jest taka sama, a wskaźniki lepsze. Brak ryzyka regresji budżetowej oznacza, że to upgrade do zrobienia w jednym sprincie.
Czy Opus 4.8 zastąpi juniorów w polskich firmach?
Nie w sensie wymiany 1:1. Realnie zmienia natomiast proporcje pracy w zespole: rutynowe taski (testy jednostkowe, refaktory mechaniczne, dokumentacja) coraz bardziej idą do agenta, a juniorzy częściej operują jako recenzenci i ownerzy konkretnych modułów.
Jakie są limity Opus 4.8 dla polskich projektów?
Model wciąż wymaga ostrożnej polityki w kontekście danych klienta — zwłaszcza dla branż regulowanych (banki, medyczne, publiczne). Wzrost „honesty" pomaga, ale nie zwalnia z konieczności wdrożenia własnych guardraili i polityki AI w firmie.
Czy benchmarki Anthropic odpowiadają realiom mojego projektu?
Tylko częściowo. Benchmarki to syntetyczne taski w angielskojęzycznym repo. Polski kod, polskie komentarze i polskie domeny biznesowe wymagają własnego testu na własnym repo — to 1-2 dni pracy seniora i warto je spalić.
Podsumowanie
- Opus 4.8 to inkrement, ale praktycznie znaczący — +4,9 pp w agentic coding to próg, od którego nowe kategorie tasków stają się delegowalne autonomicznie.
- Mniej przeoczonych błędów ~4× to zmiana wiarygodności, nie tylko jakości — agent zaczyna być realnym filtrem w code review.
- Cena bez zmian to silny sygnał konkurencyjny — okno na re-test własnego workflow z lepszym stosunkiem wartości do kosztu.
- Nie zmieniaj wszystkiego od razu — uruchom audyt, re-test, politykę AI. W tej kolejności.

